
For those who would rather just read the code: https://github.com/calebshortt/pwanalysis
[Updated April 16, 2019] I have included further results in an update at the bottom of this post.
Introduction
A study.
On many a dreary evening, once the sun sets beyond the Pacific and leaves only the gold and pink flakes of cloud and sky, I take to my studies — in the literal sense. On my desktop I maintain a growing number of “Studies” that pique my interest and encourage further research. When time permits I dive into one and if such a study bears fruit it will find its way upon these pages.
This study continues my obsession with passwords.
Firstly, I must ask you a question: Have you ever read through a password dump?
I do not mean to ask if you perused the listing then used it in some attack, but did you truly “digest” the list of passwords one by one? Did you consider their meaning or guess on the context in which they were conjured within the mind of one unsuspecting human and in which immensely intimate feelings and thoughts often manifest themselves? For who chooses a password with the thought that this very string of characters, words, symbols, and what-have-you would one day be revealed in its entirety to the world?
“*Gasp!* Plaintext?”, you balk, “But this is 2019!”. Perhaps you should ask Facebook what year it is.
I have found that passwords often reveal much more about an individual than the crude challenge-answer mechanisms utilized for authentication. If a user’s digital identity (i.e. username, etc.) is their public-facing persona then their password is often their private form. It was through my inspection of these password lists that I encountered three thoughts:
- “Password language” is a language all it’s own and it DOES have loosely established, unspoken, syntax rules.
- The frequency distribution of characters in passwords could be quite different to a spoken language frequency distribution.
- The relationship between the personality of a user and their password is non-random (sounds obvious)
My Claim:
It is not enough to simply have unique passwords. There are ways to generate passwords that are not found in a word list AND can have better results than a full brute-force attack.
And thus my journey began.
Let’s hash out these thoughts a bit more…
Thoughts
Thought 1: Password Rules as a Language
Even without the mountain of research and rule-sets available for Hashcat we need only look at the body of information security standards to see this. Both NIST SP 800-53 and ISO 27002 have general rules around passwords that create an environment which can be interpreted as a language. Let us look at some common rules:
Must have X of the following (if not all)
- Upper-case letter
- Lower-case letter
- A number/digit
- A special character/symbol
- Minimum length of 8
Looks like a language definition to me. The “language” creates a single valid password with respect to whatever policy/standard/etc. that is used.
Interesting … If I apply some predictive language models to this I might get some interesting results… Hmmm.
Thought 2: Frequency Distribution of Characters in Passwords
This seems obvious: Given the language rules outlined in “Thought 1”, a character-frequency distribution that differs from other languages would emerge. I suspect that similarities would exist to whatever language the “password maker” speaks, but they would not be the same.
For example:
If I require all words in a language to have at least one number in them I will significantly skew the frequency distribution of characters:
- English Letters: a-z: 26 possible options
- Numbers: 0-9: 10 possible options
A “password maker” (human) will have 10 possible numbers to choose from for their required number but will have 26 possible letters to choose from for the rest of the password. How many English words have a letter AND a number in them? This not only changes frequency distributions, it also makes passwords a bit easier to identify in a large corpus of English text… Interesting. I used this technique in my pastebin scraper: https://github.com/calebshortt/pastebin-scraper
Spoiler: You get into trouble with encrypted text and when people post code, but still possible. I had to train an ANN to differentiate.
All of this to simply say that if you require non-standard characters in a language it will uniquely skew the language’s character-frequency distribution.
Important foreshadowing: This means that, if we were to generate passwords on a predictive model, we would have to recalculate the frequency distributions of the “password” language… but HOW???
Thought 3: The Non-Randomness of Personality and Passwords
Now let’s get philosophical.
*pulls up a backwards chair and sits while resting arms on the back #CdrRiker*
The first time I encountered this was when I was looking at a pastebin paste of passwords from a fake porn site. I kept noticing certain passwords popping up. The same ones. Things like batman, and semperfi. Now I am not so naive to think that someone would use their banking password for a porn site — I sure hope not. There were plenty of “f-you scammer” style passwords out there too. This is why actually looking at what is in the password dumps are important. Filtering is an important phase.
Now ‘semperfi’ caught my attention (‘batman’ did too, but for different reasons. He’s obviously better than Superman). SemperFi for the uninitiated is the motto of the US Marines. It is short for “Semper fidelis” which is Latin for “always loyal”. Very nice motto and all, but why was it popping up en-masse in password dumps. Turns out the associated emails definitely gave off a … military vibe.
I suppose this is a good time to say: Worry not! all of the pastes I find are reported immediately and I do not save any of them. I look but will not touch.
Back to the thought: Non-randomness. Personality and passwords.
Turns out that correlations exist. I started looking for similar correlations in classic password dumps like “RockYou”, “MySpace”, etc. For example, some form of “batman” pops up 906 times, and “semper” 195 times, in RockYou (total of 14,344,392 passwords). Batman wins.
What is even more interesting is that you get even more information from these passwords. It isn’t just the “semperfi” aspect. Remember that a number is usually required — this usually manifests in the form of a year… The year they joined the military. Some have their state of origin, their gender, birthdays, etc. Lots going on here.
The point? Non-randomness. Again, this seems obvious, but it is an important point when thinking of creating predictive models based on such data.
Now What?
With these thoughts in mind, I started contemplating a mechanism to take advantage of these flaws in the password armour (It could be argued that ‘password armour’ is nothing more than a tattered cloth that barely covers the intimate portions of the wearer. Be careful of strong winds).
The Algorithm
My thoughts immediately went to frequency analysis. I needed to confirm that my suspicion (Thought 2) was correct. For this, I resorted to the RockYou password dump. Remember the RockYou password has around 14 million passwords. The interesting thing about RockYou is that these are non-throw-away plaintext passwords. This is a rare occurrence and getting your hands on such a password dump for analysis is VERY rare.
You can listen to the history and context around RockYou and why it is such an important password dump at a recent Darknet Diaries podcast episode. Very informative and interesting!
My second goal would be to generate a predictive model based on an existing corpus of the “password language”. This, again, would require RockYou. I played around with a few methods but settled on generating a Markov Model based on the password list. I looked around and Hashcat has a bruteforce++ method that uses a Markov chain based on the RockYou password list as well.
I was also interested in all of the possible ngrams generated for a password dump. If I could extend the single character Markov models to use any-sized ngrams for password generation my results may see improvement.
I would use the generated Markov model to create net new passwords that have not been seen in the word list but follow the same “password language” rules.
My Third goal was to add a final filter layer that acts as a verification check against all of the generated passwords. A Markov model (even with tweaking) can generate a wide range of “potential passwords” that will have a high variance from the parent dataset. This is required for a good generator algorithm, but if the “reins” are too loose we approach general bruteforce run-times.
Frequency Analysis
This was the easy part: Write a script to go through every password in the list and count the number of unique characters.
I expanded this script to generate and count all possible ngrams in each password for the entire list. A single character is just an ngram of size 1, so I just looped for all possible-sized ngrams. This ended up helping with the Markov model generation later.
For reference:
- The RockYou password list is roughly 133MB in size
- The list of generated ngrams was ~3.7GB (Contains all duplicates)
- The counted list of ngrams was ~1.39GB (No duplicates — just ngram and count per line)
The generation of such data required a streaming style programming paradigm as it is not a good idea to assume that you can load the entire file into memory. A significant amount of the programming effort was spent here as MemoryErrors can pop up in lots of places where you don’t expect them to.
To answer the character frequency question, I generated a bar chart of the top 50 characters from the password lists.
NOTE: The trailing off after ‘C’ continued into obscurity. This is a full count of characters derived from all NGRAMS.
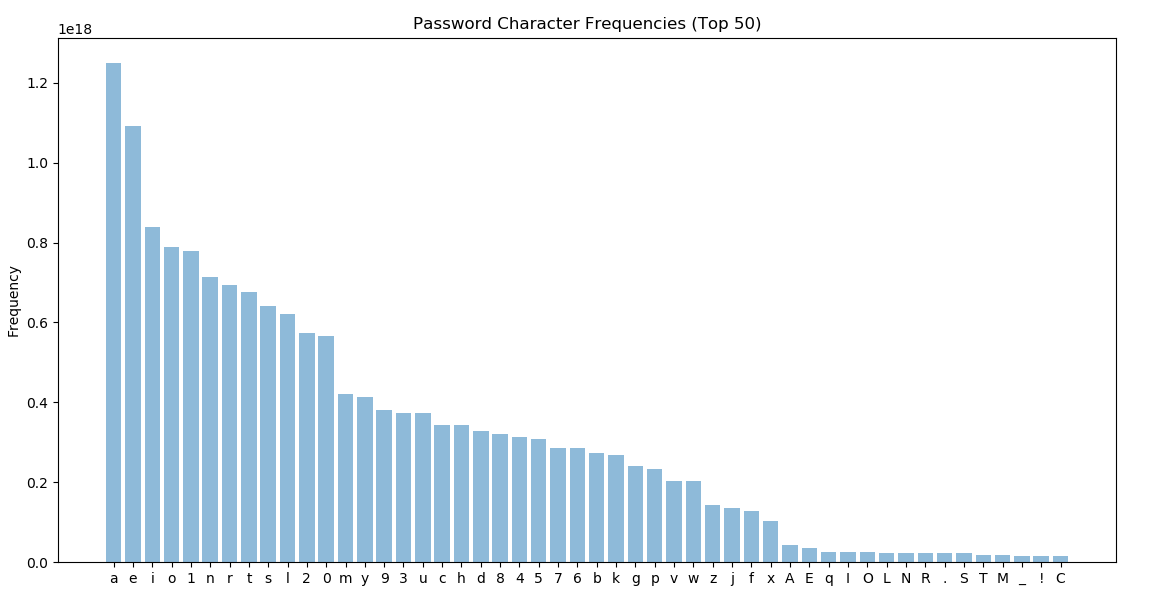
The above bar chart shows that my suspicion was correct. The frequency distribution of characters in the “password language” is slightly different than the usual (primarily English) language.
Generating a Model and then Passwords
This process required ingestion of the ngram count file (~1.39GB), generation of a Markov model based on the ngram count file, then generation of new passwords based on the Markov Model.
Again, a streaming programming paradigm was taken to not load the entire dataset into memory. The generation of the Markov model was relatively simple.
First another counting and structuring exercise was complete: Each ngram was broken down into characters and iterated through. The current character was treated as a node while the next character would then be a child of that node with the ngram’s count associated to it. This allowed for the cumulative counts to be applied to each relationship within the ngram.
For example, if the ngram was “root” with a count of 100:
- Current character: ‘r’
- ‘o’ follows ‘r’: Add a child called ‘o’ with count 100 to top-level ‘r’ node.
- Current character: ‘o’
- ‘o’ follows ‘o’: Add a child called ‘o’ with count 100 to top-level ‘o’ node.
- Current character: ‘o’
- ‘t’ follows ‘o’: Add a child called ‘t’ with count 100 to top-level ‘o’ node.
Then, once the data structure is built we can normalize it using the total count to generate probabilities for each node. This will make our Markov model satisfy the property that each path must add to 1 (i.e. 100%).
Now the model is complete and we can use it to generate a new password … but how do we choose the very first character of our password? This is where our character frequency distribution map chimes in. I use this map to select a random character that is weighted based on the frequency distribution we generated (Remember we can’t use an English one — has to be based on the ‘password language’).
Now we have a basic password generator that is using weighted random selection of the first character, then generating the remaining password from a Markov model built from the RockYou password list. All we have to do is tell it when to stop — that is, how long we want the password to be (8 characters? 10? etc.).
An improvement
I ran the generator and analyzed the results. It sure worked, but there were a few low-frequency characters that would never show up in the generated passwords. These weren’t a huge deal as they were low probability, but I took a page from the genetic algorithm playbook and included a “mutation” value that I could configure. This would add a randomization element to the generation of a password and potentially avoid any “local minima passwords” (passwords that are so common that they override the probability of similar passwords — which would then never be produced). The results seemed to produce a better “population” of passwords.
Filtering Generated Passwords
Now that I have a set of generated passwords I could start using them and compare the results against other brute-force algorithms such as the Hashcat one. But first I wanted to build a filtering mechanism to help hone the generated passwords.
The problem with generated passwords is that they vary. A lot. This is both good and bad.

The lines in the above diagram needs some explaining. If we think about generated password variance, we are thinking about how our generated password varies from what we would consider an actual password. The above diagram attempts to use the ‘B’ line as a representation of a ‘perfectly’ generated password (the generated password fully reflects what the model thinks is a password and IS a password). As we horizontally move away from the ‘B’ line in either direction we start to diverge from what we think is a password and what IS a password.
- If we move to the left from B, our model ‘thinks’ the string looks like a password but it starts to be LESS probable that it actually is a password.
- If we move to the right, our model starts to ‘think’ the string doesn’t look like a password but it starts to be MORE probable that it actually is a password.
- The lines A and C represent some bound that I was hoping to keep my model within as to not get too far away from the center of this diagram. I suspect that there is a correlation between the distance from the center B line and the entropy in the password — I would consider a high entropy password to be at the far right of the “strings that are passwords” category. This is a string that my algorithm would never generate.
The problem is that the only way to check if a string not only looks like a password but actually is a password is to verify it with known passwords. This isn’t always possible (Obvious reasons). Some sort of filter or measure of “password likeness” would help here. It would at best be a heuristic but it may still provide the model with some guidance.
Enter the machine learning aspect of the system.
This is a classic 2-label classification problem: “Password” and “Not password”. The problem is that “Not password” is not a helpful term. At any point a “Not password” string could be used as a password and change categories. Not fun. Also, training an algorithm requires a LABELED dataset (unless I start to look at unsupervised clustering algorithms). I had a list of passwords — a labeled set, but no “no password” list.
I went for a unary classifier. To be specific, I used scikit-learn’s single class SVM with a non-linear kernel. This I trained with my known ‘password’ list. The goal here was not to be 100% accurate — in fact an algorithm that was 100% accurate against my training set (no matter how large) would signal a serious issue (over-fitting). In reality, I was hoping for a range of inaccuracies because by definition my generated password would not be in the training dataset. I wanted an algorithm that measured more of a “looks close enough to be a password based on what I’ve seen” vibe.
I trained the classifier on the same dataset that the Markov models were generated from — the RockYou dataset. This could be considered adequate or poor form based on who you talk to — I will leave this as a future exercise to retrain the classifier on a different dataset and see how the results differ. The ultimate goal of classifier was to filter out generated passwords that differed too greatly from the ‘established norm’ … in essence, that B line in the Venn Diagram above.
This “verifier” was put in front of the password generator to filter its results. Depending on its configuration it could block any generated password that differed too greatly from its training set. This ultimately resulted in only passwords that looked like a RockYou password (but weren’t actually in the RockYou dataset) passing through the filter.
Results, Conclusions, and Future Work
Passwords were generated! These passwords looked close enough to real passwords from visual inspection that I am satisfied that this method could be useful. With that said, tweaking is always required. I think I can do better. My system would also benefit from a numerical comparison of passwords such as Hamming distance or other string similarity algorithms. This could better inform my classifier.
As far as lessons learned, I had quite a time coding up a way to handle counting a dataset where I could not even store my counts in memory, so had to get creative. Learned a lot about the limits of Python and memory allocation, and a few tricks to keep your application from tipping things over.
I am interested in testing this framework further to see how much better the generated passwords are against a standard Markov model-generated password set. I would have to evaluate it based on number of passwords compared and not timing as optimizations in that space can always be made.
What is interesting about this method is that the resulting passwords could be generated for any length, then hashed and placed in a rainbow table — this would create a rainbow table of arbitrary-length passwords that have some similarity to actual passwords. I suspect a better hit rate when all wordlists fail and you have time to precompute a huge list of passwords.
Other future work: There are plenty of places for improvement. My code is littered with “TODOs” where I have identified issues or potential areas for improvement. I would like to improve the Markov model usage to include ngrams of length >1 — this project was only on single characters.
If you are interested in the code and don’t want to scroll back up to the top, here it is:
https://github.com/calebshortt/pwanalysis
Update: Analysis of the Generated Passwords
April 16, 2019. My continued work and analysis has generated some results on this topic and so I will post them here.
This update will outline in more detail the generated passwords and my resulting analysis on these passwords to ensure that they are generated and validated correctly.
Generated Passwords and their Source Material
Let us look at a list of generated passwords (from my tool) and the list of passwords from the source material. In this case I used the rockyou password dump as source material.
Generated Passwords (Of length 8, with validation) Sample:
enleiffa ngegiena leetlolo ramtiohe uisshler whoenioa iacilele setlmsii kioaeil3
The tool currently requires the user to specify a password length. For example the user will ask the tool to generate 1000 passwords of length 8 based on the given source dump. Remember, validation uses a trained model filter which only allows passwords that have been classified as ‘passwords’. This second level of validation prevents the raw generation of passwords from the Markov Model from diverging too much from the source content (Remember that I included a ‘mutation’ aspect to the model in an attempt to inject variance in the password ‘population’, this additional filter keeps that mutation aspect in check).
Here are a few generated passwords without validation enabled:
2&0๑1003 02957878 weeaihie teehieőc onvlk0nl oturnnor laeillòe 6M574872 hoooaol9
The set of passwords generated in this way can be thought of as a superset of the validated passwords. All passwords generated in the raw, nonvalidated form will include the validated passwords — just with more noise. Also notice the increase use of characters that are not in the ASCII set but are in the UTF-8 character set. This is because the model generated from rockyou included these lower probability paths.
Methods: Comparison and Similarities
My method for comparing the generated passwords against the source material is relatively straight-forward.
When comparing strings one generally tends to think of either Hamming or Levenshtein Distances. There are others I know but I will limit my assessments to these two as I am not trying to spark a debate on the merits of various string comparison algorithms.
Hamming Distances are great comparison calculations if the two strings are equal lengths. This works by counting the number of character positions in a string that differ from another string. E.g. hamming_distance(abc, abb) = 1 as only one character position differs. I could not, and did not, want to guarantee this property when comparing my generated passwords to their source. Length is an important value in the comparison, and in the future I want my tool to make the decision to terminate the string (password) by itself thus determining length automatically.
Levenshtein Distances can compare two strings of different lengths. This is done by counting the number of insertions, deletions, and substitutions required to match the strings. This method compensates for length variation with the insertion and deletion methods (whereas Hamming Distances can sort-of be thought as a L. Distance with only the ‘substitution’ property). I chose Levenshtein Distance as my string metric as I wanted to use variable-length strings.
In practicality, I chose the Levenshtein Ratio (just the L. Distance over alignment length). This gives me a normalized value from 0.0 to 1.0 that I can work with.
I used the python-Levenshtein library to execute the actual calculation.
Process
My analysis included the following steps:
- Run validated password generation using rockyou as the source (Generate 1000 sample passwords)
- Run nonvalidated password generation using rockyou as the source (Generate 1000 sample passwords)
- Calculate the Levenshtein Ratio for each generated dataset (compare with rockyou)
Analysis of Results
I generated four sets or passwords for my initial assessment:
- Validated passwords of length 8
- Validated passwords of length 9
- Nonvalidated passwords of length 8
- Nonvalidated passwords of length 9
For each password set I compared them against the rockyou source using the Levenshtein ratio.
Here are the results (NOTE: The ratio is from 0.0 to 1.0. The higher the ratio the higher the similarity between the sets):
- Validated passwords of length 8
- L. Ratio Compared to Whole RockYou DataSet: 0.99561
- L. Ratio Compared to Top 1000 RockYou Passwords: 0.99923
- Validated passwords of length 9
- L. Ratio Compared to Whole RockYou DataSet: 0.99563
- L. Ratio Compared to Top 1000 RockYou Passwords: 0.99924
- Nonvalidated passwords of length 8
- L. Ratio Compared to Whole RockYou DataSet: 0.99560
- L. Ratio Compared to Top 1000 RockYou Passwords: 0.99923
- Nonvalidated passwords of length 9
- L. Ratio Compared to Whole RockYou DataSet: 0.99560
- L. Ratio Compared to Top 1000 RockYou Passwords: 0.99922
After I ran the initial evaluations against the entire rockyou dataset I wanted to see how my values compared to just the top 1000 rockyou passwords. This would compare my 1000 generated passwords to the top 1000 passwords in rockyou. As you can see above I was quite happy with the results.
The comparison between the entire rockyou dataset showed roughly a ratio of 0.995 whereas the ratio of the top 1000 comparisons was 0.999. This makes sense as the rockyou dataset is roughly 14 million entries. This would include significantly more variance than the top 1000. With that said, the top 1000 passwords of rockyou are often enough (with perhaps some HashCat rule trickery) to crack plenty of passwords.
As I ran the generator in validation mode for passwords of length 10 or greater I noticed a significant drop-off in production. This was not due to the tool’s inability to produce passwords of length 10+ but in the validation model’s ability to tell if the generated strings of length 10+ were sufficiently similar to the password dataset to allow through. The validation step was filtering out most of the passwords that were generated. Unfortunately the solution would be to relax some of the constraints on the model and allow for more variance — which would have invalidated the consistency of my results. I chose to only do validated passwords of length 8 and 9 for now and to look into more agile models than the Single Class SVM I was using.
With that said, I ran my comparisons on all nonvalidated results with interesting outcomes:
- Nonvalidated passwords of length 10 against the top 1000: 0.99922
- Nonvalidated passwords of length 11 against the top 1000: 0.99922
- Nonvalidated passwords of length 12 against the top 1000: 0.99921
- Nonvalidated passwords of length 13 against the top 1000: 0.99921
- Nonvalidated passwords of length 14 against the top 1000: 0.99921
- Nonvalidated passwords of length 15 against the top 1000: 0.99920
- Nonvalidated passwords of length 16 against the top 1000: 0.99920
- Nonvalidated passwords of length 17 against the top 1000: 0.99920
Notice that as the password length increases there isn’t much of a change in the Levenshtein Ratio. There is a downward trend, but only very slightly.
Final Remarks on Results
Considering the similarity ratios calculated, if I were to use this tool in a practical sense, I would simply forego the validation step and generate the nonvalidated passwords as their similarity calculations are very close to those of the validated sets. The difference is the significant time required to generate passwords of length 10 (or more) that can pass the validation step.
It is important to note that the passwords generated were not already in the rockyou dataset (no overlap). This means that my tool can be used as an intermediate step — between “naive” brute forcing and using a dictionary. This method can be thought of as a type of “password squeeze problem” as it is close enough to the source dataset to possibly provide useful alternatives that may not be found within the dataset itself.

You must be logged in to post a comment.